Проблемы событийной аналитики
Событийная аналитика – это механизм анализа работы информационных систем, основанный на законе больших чисел. Поток дискретных событий, генерируемый системой, записывается в хранилище данных вместе с метаданными, описывающими контекст возникновения события: время, гео, ID сессии/пользователя, источник трафика и т. п. Массив записанных событий далее используется для распределения пользователей по когортам, построения воронок продаж, расчета метрик, т. е. причинно-следственные связи между событиями устанавливаются статистически. Событийная аналитика в настоящее время является стандартом де-факто (Mixpanel, Amplitude, Google Analytics и т. д.), придя на смену сессионной, однако у такого подхода есть ряд фундаментальных проблем.
Время – это способ упорядочения действующих причин и накапливающихся следствий.
Алексей Семихатов. Прогулки по беспокойной вселенной.
Всякое событие в типичной аналитической системе содержит одно обязательное поле – это имя события (например, event_name), позволяющее однозначно определить тип события. На этом стабильность заканчивается, все остальные параметры являются либо опциональными, либо ненадежными. Рассмотрим пример ниже:
{
"event_name": "order_paid",
"timestamp": "2026-02-07T10:12:33.120Z",
"user_id": "u_123",
"session_id": "s_456",
"properties": { "amount": 1290, "currency": "RUB", "method": "apple_pay" },
"context": { "app_version": "7.1.0", "os": "iOS", "locale": "ru_RU" }
}Поле timestamp отражает момент регистрации события. Современные информационные системы в абсолютном большинстве являются распределенными, что неминуемо означает расхождение в часах между сервером и клиентами. Если определить timestamp как момент поступления события на единый общий сервер, то это значение будет включать в себя время путешествия события по сети. События могли быть созданы в одном порядке, а добраться до сервера уже в другом. Если определить timestamp как момент создания события на клиенте, то сервер уже не сможет гарантировать правильный временной порядок событий между разными клиентами. Таким образом, надежно формировать причинно-следственный порядок событий с помощью только timestamp на практике не удается.
Поля user_id и session_id в теории позволяют идентифицировать принадлежность события к некоторой группе, но что делать, если пользовательские cookies по каким-либо причинам оказались стерты? Можно вообще не регистрировать такие события, но это означает потерю данных в моменте и ухудшение качества (репрезентативности) общего набора данных в целом.
Поле context в общем случае вычисляется на основе технических параметров системы и исторически использовалось для идентификации клиента (user-agent, уникальный device-id и т.д.). С течением времени клиентские платформы (браузеры и мобильные ОС) все больше «закручивали гайки», блокируя механизмы отслеживания пользователей. В настоящее время однозначно полагаться на контекст тоже уже нельзя.
Поле properties описывает контекст уровня приложения, технически туда можно поместить значительный объем информации, однако в высоконагруженных системах каждый байт в пэйлоаде события оборачивается гигабайтами дополнительного трафика. «Всё» поместить в properties не получится, и установку связей между событиями через общий контекст приходится всякий раз решать в частном порядке.
Все это приводит к тому, что события регистрируются в системе фрагментарно, изолированно друг от друга. Вместе с тем для построения каких-либо выводов аналитику нужно установить причинно-следственную связь между событиями. Это напоминает «Войну и мир», пропущенную через шредер: в содержимом на выходе определенно есть какие-то данные, но как их оттуда извлечь? Таким образом, можно сформулировать первое ограничение событийной аналитики в условиях отсутствия синхронизации: для выявления причинно-следственных связей нужны A/B-тесты.
Второй фундаментальной проблемой событийной аналитики являются неполнота и дублирование запросов в последовательностях. Теоретически для регистрации клиентского события, например, нажатия на кнопку «Заказать», клиент должен выполнить идемпотентный запрос к аналитической системе, т. е. каким-либо образом гарантировать, что регистрация события будет выполнена однократно. На практике поток событий чрезвычайно интенсивен, поэтому в целях оптимизации процесса записи события обычно регистрируются в системе без предварительной проверки на уникальность. Такая проверка требует сопоставления идентификаторов, т. е. дополнительных запросов на чтение. Можно использовать кэши, но они всегда имеют ограничение по размеру окна обработки. Кроме того, как было показано выше, события в общем случае не связаны между собой. Если нет общего для двух событий user_id, затруднительно отличить retry-запись, возникшую из-за сбоя сети, и повторную запись, обусловленную повторным действием пользователя. Также сложно задетектировать пропущенный запрос. Таким образом, дублирование и неполнота запросов в исходных данных осложняют проведение статистически значимых A/B-тестов.
Совокупность этих двух фундаментальных ограничений приводит к уже прикладным проблемам в событийной аналитике, которые возникают всегда, независимо от того, насколько совершенный инструментарий применяется.
Во-первых, численную аналитику обычно всерьёз начинают применять и воспринимать только тогда, когда начинает подводить интуиция. Интуиция отлично работает в зоне «низковисящих фруктов», т. е. очевидных идей и здравого смысла, сформированного жизненным опытом конкретного индивида. Если же все «низковисящие фрукты» собраны, приходится довольствоваться снижением минимально приемлемой разницы в результатах эксперимента, а на малых значениях уже нужна «честная» математика. Калькулятор A/B-тестов наглядно демонстрирует, что уменьшение Minimum Detectable Effect в 10 раз приводит к увеличению выборки Sample size в 100 раз, а стократное снижение минимального эффекта требует увеличения выборки в 10 тысяч раз! Иными словами, стоимость эксперимента растет по квадратичному закону.
// 5%
Baseline conversion rate: 20%
Minimum Detectable Effect: 5%
Statistical power 1−β: 80%
Significance level α: 5%
Question: How many subjects are needed for an A/B test?
Answer: 1030 per variation
// 0.5%
Baseline conversion rate: 20%
Minimum Detectable Effect: 0.5%
Statistical power 1−β: 80%
Significance level α: 5%
Question: How many subjects are needed for an A/B test?
Answer: 100746 per variation
// 0.05%
Baseline conversion rate: 20%
Minimum Detectable Effect: 0.05%
Statistical power 1−β: 80%
Significance level α: 5%
Question: How many subjects are needed for an A/B test?
Answer: 10049393 per variation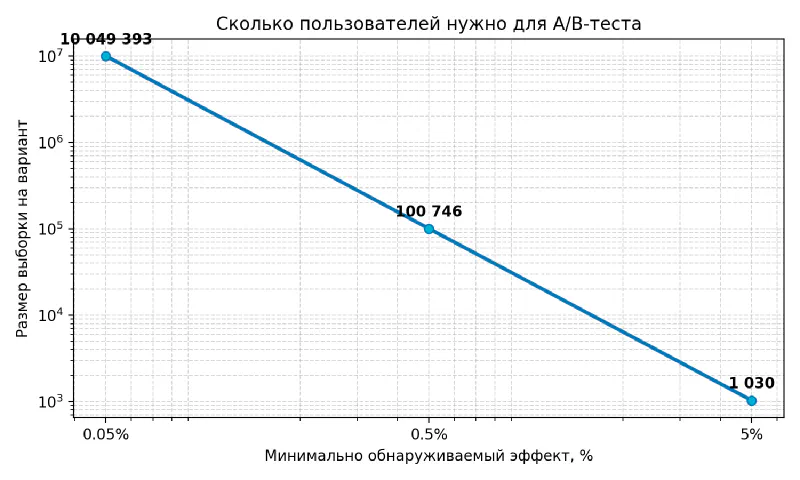
Увеличение размера выборки означает увеличение затрат: либо нужна большая аудитория, либо тест нужно держать долго, отнимая аудиторию у других тестов. Долго – значит дорого!
Кроме того, длительность эксперимента может негативно сказаться на оперативности принимаемых решений. Статистический эффект, заметный на момент проведения теста, может оказаться неактуальным к моменту внедрения, если период между этими моментами слишком большой. Например, в сфере аренды недвижимости в курортных регионах спрос имеет ярко выраженный сезонный характер.
Во-вторых, усреднение по большой выборке может приводить к потере локальных значений. Может так получиться, что часть аудитории внутри выборки отреагировала на эксперимент положительно, а другая часть – отрицательно. В сумме A/B-тест «не прокрасился», хотя на самом деле эффект в двух когортах по отдельности был значительным. Используя усреднение, мы рискуем построить сервис, одинаково неудобный для всех. Для того чтобы разделить аудиторию на когорты с однородным поведением, аналитикам приходится выполнять много «ручной» работы по выявлению подходящих ковариат и последующему когортированию. Расчет делается на то, что статистическая значимость в отдельно взятой когорте получить легче. В общем случае при поиске подходящих ковариат снова приходится полагаться на «здравый смысл», запуская новые и новые эксперименты, при этом без гарантии результата.
В-третьих, попадание пользователя в некоторую когорту вовсе не гарантирует однородность его поведения. Как только мы снижаем размер выборки, проводя эксперимент в отдельной когорте, роль индивидуальных пользовательских конфаундеров резко возрастает. Один и тот же пользователь может утром, будучи бодрым и отдохнувшим, принять одно решение, а вечером, после утомительного рабочего дня – совсем другое. Результаты эксперимента, проведенного утром, будут неактуальны для конкретного пользователя в его «вечернем» состоянии. Снижение размера выборки делает выбранное сочетание ковариат менее устойчивым, а в задачах персонализации зачастую вообще неприменимым.
Таким образом, аналитика, построенная на A/B-тестах, дает математически гарантированный результат, но цена статистической значимости тоже математически неэластична и может оказаться неприемлемой. Попытки снизить «статистическую цену» за счет предварительной подготовки данных приводят как к росту трудозатрат аналитиков и разработчиков, так и к радикальному усложнению механизмов событийной аналитики. Поиск альтернативных метрик, которые окажутся более чувствительными к «серому» A/B-тесту, приводит к разрастанию набора метрик, что осложняет последующий бизнес-анализ.
«Ускорителем» событийной аналитики может послужить трассировка событий, в которой причины и следствия формируются явным образом в виде последовательности событий, связанных отношением «родитель-потомок». Событие-родитель может являться причиной (условием) для события-потомка, но потомок не может быть причиной для родителя. Для того чтобы этого достичь, архитектура информационной системы должна быть сформирована таким образом, чтобы у всякого события гарантированно были собственные идентификаторы uuid и parent_uuid (например, в формате UUID v4):
{
"uuid": "b9172231-b37f-436e-b8fc-e73e762f2dac",
"parent_uuid": "c40435de-e822-4ea5-adb0-8d63ca083d16",
"event_name": "order_paid",
"timestamp": "2026-02-07T10:12:33.120Z",
"user_id": "u_123",
"session_id": "s_456",
"properties": { "amount": 1290, "currency": "RUB", "method": "apple_pay" },
"context": { "app_version": "7.1.0", "os": "iOS", "locale": "ru_RU" }
}Такая гарантия дает возможность детектировать процессы, протекающие в информационных системах, для каждого пользователя в отдельности, адресно. Это позволяет по-прежнему применять закон больших чисел и A/B-тесты, но уже на качественно иной «кормовой базе».
Поведение – это зависимость некоторой величины от времени.
Алексей Семихатов. Прогулки по беспокойной вселенной.
Во-первых, анализ и сопоставление отдельных трейсов друг с другом позволяют заменить ручной поиск ковариат и конфаундеров на автоматическое когортирование по структуре цепочки, т. е. выполнить когортирование по поведению. Если у группы пользователей в условиях данной системы наблюдается похожее поведение, то можно ожидать, что в этих же условиях индивидуальное сочетание их конфаундеров приведет к похожей реакции на эксперимент. Статистическую значимость в такой когорте получить легче.
Во-вторых, имея на руках трейсы поведения каждого пользователя, мы можем обоснованно различать, принимал ли пользователь участие в другом эксперименте. Это позволяет более уверенно сегментировать аудиторию между несколькими одновременными экспериментами и наращивать «чистый» объём выборки для каждого из экспериментов.
Наконец, анализ трейсов после эксперимента позволяет пошагово наблюдать изменение чувствительности A/B-теста на каждом спане в цепочке. Это позволяет автоматически определять метрику, на которую эксперимент оказывает влияние.
Таким образом, событийная аналитика имеет ряд фундаментальных и прикладных проблем. Вместе с тем эти проблемы можно в значительной степени нивелировать, если воспользоваться идеей трассировки событий.
Юрий Дубовой (Docingem), 9 февраля 2026 г.